云原生实践:智能计算平台构建与研发
基于Centos7.9操作系统和Docker容器引擎,构建Ollama + Gradio+ Deepseek/Qwen环境,搭建大模型本地知识库,可以为企业快速搭建本地知识库,构建企业管理的智能体,提升内部信息管理效率。
🤔 写在前面: 转载自2025 ccf培训内容
模块简介
基于Centos7.9操作系统和Docker容器引擎,构建Ollama + Gradio+ Deepseek/Qwen环境,搭建大模型本地知识库,可以为企业快速搭建本地知识库,构建企业管理的智能体,提升内部信息管理效率。
模块知识
(1)理解国产大模型(DeepSeek/Qwen)的技术特点与应用场景;
(2)掌握 Ollama 实现大模型本地部署的核心原理;
(3)理解服务网格与声明式 API 在云原生架构中的作用;
(4)能独立完成 CentOS 环境下 Docker+Ollama 的离线部署;
(5)能通过 Dify 平台构建企业本地知识库与智能体应用;
(6)能使用 Gradio 开发大模型交互界面。
环境准备
使用线上平台提供的实验环境,准备一台CentOS 7.9操作系统的虚拟机,一台桌面化测试环境。实验节点的具体规划见表1。
表1 节点规划
| IP | 主机名 | 节点 |
|---|---|---|
| 192.168.100.23 | ollama | 大模型节点 |
| - | localhost | 桌面化测试环境 |
模块内容
1. 大模型平台介绍
本项目通过构建Docker+Ollama + Gradio容器化环境,以构建一个企业本地知识库,实现助手智能体。

图1 项目示意
1.1 DeepSeek/Qwen国产大模型介绍
DeepSeek 的 AI 大模型是国产之光,千亿参数规模下,API 调用成本低至 0.5 元/百万 tokens,中文基准测试得分高达 91.5%,推理效率还比传统架构提升了 5 倍。基于DeepSeek企业能轻松搭建本地知识库,提升信息管理效率。

图2 DeepSeek产品
千问大模型堪称国产大模型领域的 “超级明星”。它有着千亿级别的参数规模,依托千问大模型,企业能够轻松搭建本地知识库。通过对企业内部各类文档、资料、数据的整合与分析,模型可以快速定位和提供准确信息,极大地提升企业信息管理效率,帮助员工快速获取所需知识,减少查找信息的时间成本,为企业决策提供有力的数据支持。

图3 千问大模型
1.2 Ollama:简化本地部署
Ollama 是一个开源的本地化工具,专门用来简化大型语言模型的本地运行和部署。它能让用户在个人计算机或服务器上轻松运行多种开源语言大模型,比如 DeepSeek、Qwen、Llama 等,完全不依赖云端服务,也不用复杂配置。

图4 Ollama 开源的本地化工具
1.3 Gradio可视化界面
Gradio是一个搭建可视化界面的Python库,也是一个强大且易用的工具,可以帮助开发者快速构建交互式的机器学习模型展示界面。它提供了一个简单易用的界面搭建框架,让用户可以很容易地将模型部署为一个交互式的Web应用程序,而无需编写任何前端代码。
Gradio支持各种类型的输入数据,包括文本、图像、音频和视频,让用户可以通过简单的拖放操作来测试和调整模型。用户可以自定义界面的样式和布局,添加各种控件来与模型交互,比如滑块、文本框、下拉菜单等。
通过Gradio,用户可以快速构建一个漂亮的Web应用程序,用于展示自己的机器学习模型,与其他人分享模型的功能和性能,或者用于实际的应用场景中。

图5 Gradio可视化界面
2. 实战案例——搭建大模型平台
2.1 Docker离线部署
下载docker-20.10.20.tgz、dify_images.tar.gz、models.tar.gz、dify-main.zip软件包,这些软件包分别用于安装Docker、Dify镜像导入、离线大模型导入Ollama管理平台和Dify容器化安装。将软件包下载到大模型节点上,并进行Docker服务的安装。
首先修改主机名,修改完成后点击左边工具栏的”重连”按钮,或者使用bash命令进行刷新:
1 | [root@res-n18437027226-f2exsogjhi ~]# hostnamectl set-hostname ollama |
开始下载软件包4个软件包:
1 | [root@ollama ~]# curl -O http://mirrors.douxuedu.com/newcloud/docker-20.10.20.tgz |
开始安装Docker服务,先解压 Docker 二进制文件包,并且把解压得到的可执行文件复制到/usr/bin/目录:
1 | [root@ollama ~]# tar zxvf docker-20.10.20.tgz |
创建一个 systemd 服务配置文件,其目的是将 Docker 作为系统服务进行管理。配置文件里定义了服务的描述、启动顺序、执行命令以及重启策略等内容。
1 | [root@ollama ~]# cat >> /usr/lib/systemd/system/docker.service <<EOF |
启动并启用 Docker 服务,命令如下:
1 | [root@ollama ~]# systemctl daemon-reload && systemctl restart docker && systemctl enable docker |
配置 Docker 镜像加速和 cgroup 驱动,最后重新加载配置并重启 Docker,命令如下:
1 | [root@ollama ~]# cat >>/etc/docker/daemon.json << EOF |
Docker 是一个开源的应用容器引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者在本地编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机)、bare metal、OpenStack 集群和其他的基础应用平台。

图6 Docker应用容器引擎
简单的理解,Docker类似于集装箱,各式各样的货物,经过集装箱的标准化进行托管,而集装箱和集装箱之间没有影响。也就是说,Docker平台就是一个软件集装箱化平台,这就意味着我们自己可以构建应用程序,将其依赖关系一起打包到一个容器中,然后这容器就很容易运送到其他的机器上进行运行,而且非常易于装载、复制、移除,非常适合软件弹性架构。
Docker提供容器管理的工具:
- Docker CLI(Command - Line Interface):这是一个命令行工具,允许用户通过命令行输入来与 Docker 引擎进行交互。用户可以使用 CLI 来执行各种操作,如拉取镜像、创建容器、启动容器、查看容器状态等。
- Docker Compose:用于定义和运行多容器 Docker 应用程序的工具。用户可以通过一个 YAML 文件来定义应用程序中的多个容器及其配置,包括容器之间的依赖关系、网络设置、卷挂载等。
2.2 Ollama大模型管理平台容器部署
(1)基于Docker进行Ollama部署
创建/root/ollama目录,导入Dify镜像:
1 | [root@ollama ~]# mkdir /root/ollama |
部署Ollama服务,返回结果如图7所示。
1 | [root@ollama dify_images]# cd /root/ |

图7 Docker部署
正常运行后,可以登录网站进行查看Ollama的状态,如图8所示:

图8 查看Ollama的状态
(2)离线部署大模型
进入到Ollama模型存储目录,将打包好的models.tar.gz离线模型软件包解压到存储目录中,如图9所示,命令如下:
1 | [root@ollama ~]# cd /root/ollama/ |

图9 解压models.tar.gz
解压完成后,进行验证,查看是否成功部署离线模型,如图10所示,命令如下:
1 | [root@ollama ollama]# docker exec -it ollama bash |

图10 验证
可以看到,模型成功被导入到Ollama中。
2.3 Dify 容器编排部署
(1)安装 Dify 环境
首先需要配置Yum源仓库,安装依赖工具,命令如下:
1 | [root@ollama ollama]# rm -rf /etc/yum.repos.d/* |
将下载的dify-main.zip源码包解压,并进入到容器化安装目录,配置环境变量,命令如下:
1 | [root@ollama ollama]# cd /root/ |
进行容器化安装Dify,首先安装Docker Compose,并修改配置,命令如下:
1 | [root@ollama docker]# curl -O http://mirrors.douxuedu.com/newcloud/docker-compose |
修改以下配置,此配置在548行。
1 | plugin_daemon: |
完整内容如下:
1 | plugin_daemon: |
最后启动Dify服务,命令如下:
1 | [root@ollama docker]# docker-compose up -d |
安装完成后,使用以下命令进行验证,检查状态是否为Up状态:
1 | [root@ollama docker]# docker-compose ps |
docker-web-1 (Web Frontend)
- 功能: 这是 Dify 的用户界面(UI)。
- 作用: 提供可视化操作界面,用户在此创建、管理、调试应用,配置提示词、数据集、模型,查看日志和分析数据等。通常基于 React 或 Vue 等前端框架构建。
- 依赖: 与
docker-api-1通信获取数据和执行操作。
docker-api-1(API Server)
- 功能: 这是 Dify 的后端核心服务,提供 RESTful API。
- 作用: 处理来自 Web 前端 (
web) 和最终用户应用的请求。负责业务逻辑,如应用管理、数据集管理(文档处理、嵌入)、提示词工程、模型调用编排、日志记录、用户管理、计费等。 - 依赖: 与数据库 (
db)、缓存 (redis)、向量数据库 (weaviate)、模型提供方(如 OpenAI, Anthropic, 本地模型等)、工作队列 (worker) 进行交互。
docker-worker-1 (Celery Worker)
- 功能: 异步任务处理引擎(通常基于 Celery)。
- 作用: 处理耗时的后台任务,避免阻塞 API 服务器的响应。典型任务包括:
- 长文本的拆分、清洗和嵌入到向量数据库(当上传数据集时)。
- 调用需要较长时间响应的模型(特别是开源大模型)。
- 生成报告、批量操作等。
- 依赖: 接收来自
docker-api-1或定时触发的任务消息(通常通过redis作为消息代理),访问数据库 (db)、向量数据库 (weaviate)、模型提供方。
docker-db-1 (PostgreSQL Database)
- 功能: 主关系型数据库(通常是 PostgreSQL)。
- 作用: 持久化存储所有结构化数据,例如:
- 用户账户信息、组织信息
- 应用配置(名称、图标、模型设置、提示词模板等)
- 数据集元数据(名称、状态、来源等)
- 对话历史记录、消息
- 日志(应用调用日志、错误日志)
- 插件配置
- 核心依赖: 被
docker-api-1和docker-worker-1频繁读写。
docker-redis-1 (Redis Cache & Message Broker)
- 功能: 内存数据存储,用作缓存和消息代理。
- 作用:
- 缓存: 缓存频繁访问的数据(如模型配置、应用配置、临时状态),减轻数据库 (
db) 压力,加速 API 响应。 - 消息代理: 作为 Celery 的后端,在
docker-api-1和docker-worker-1之间传递异步任务消息。 - 会话存储/临时数据: 可能用于存储用户会话信息或其他需要快速读写的临时数据。
- 缓存: 缓存频繁访问的数据(如模型配置、应用配置、临时状态),减轻数据库 (
- 核心依赖:
docker-api-1和docker-worker-1使用它进行缓存和任务队列通信。
docker-weaviate-1 (Weaviate Vector Database)
- 功能: 向量数据库。
- 作用: 专门用于存储和高效检索文本(或其他数据)的向量嵌入(embeddings)。这是实现 RAG(检索增强生成)功能的核心组件。
- 当用户上传文档到数据集时,
worker会将文本块转换成向量并存入 Weaviate。 - 当用户提问时,API 会将问题转换成向量,在 Weaviate 中进行相似度搜索,找到最相关的文本片段,然后将这些片段作为上下文提供给 LLM 生成更准确、基于知识的回答。
- 当用户上传文档到数据集时,
- 依赖: 主要被
docker-api-1(执行检索) 和docker-worker-1(执行嵌入和存储) 使用。
docker-plugin_daemon-1 (Plugin Daemon)
- 功能: 插件管理守护进程(在早期版本中可能直接集成在 API 里)。
- 作用: 负责加载、管理、执行和监控 Dify 平台上的插件。插件用于扩展平台功能,例如连接到外部 API(数据库查询)、执行特定工具(代码执行)、集成其他服务等。它确保插件的安全隔离(与
sandbox相关)和稳定运行。 - 依赖: 与
docker-api-1通信(API 将需要插件执行的请求转发给它),可能调用docker-sandbox-1执行非受信插件代码。
docker-sandbox-1 (Sandbox Environment)
- 功能: 代码执行沙箱(通常是基于 Firecracker 或 gVisor 的安全容器)。
- 作用: 提供一个高度隔离、资源受限的环境,用于安全地执行不受信任的代码。主要用于:
- 运行用户上传的自定义 Python 工具/插件代码。
- 可能用于执行某些需要隔离处理的数据集预处理逻辑。
- 目的: 防止恶意或错误代码影响主平台(API、Worker、数据库等)的稳定性和安全性。是平台安全性的重要保障。
- 依赖: 由
docker-plugin_daemon-1或docker-worker-1触发执行特定代码任务。
docker-nginx-1 (Nginx Reverse Proxy)
- 功能: Web 服务器和反向代理。
- 作用:
- 反向代理: 作为统一的入口点,接收外部(用户浏览器、客户端应用)的 HTTP/HTTPS 请求,并根据路径规则将请求转发到内部对应的服务(主要是
docker-web-1和docker-api-1)。例如/转发到 Web UI,/v1/转发到 API Server。 - 负载均衡(如果有多实例): 可以将请求分发到多个后端实例(虽然单机部署通常只有一个实例)。
- SSL/TLS 终止: 处理 HTTPS 加密解密。
- 静态文件服务: 可能直接提供 Web 前端的静态资源(JS, CSS, 图片)。
- 基础路由和访问控制。
- 反向代理: 作为统一的入口点,接收外部(用户浏览器、客户端应用)的 HTTP/HTTPS 请求,并根据路径规则将请求转发到内部对应的服务(主要是
- 核心依赖: 所有外部流量首先到达这里。它代理到
docker-web-1和docker-api-1。
docker-ssrf_proxy-1 (SSRF Proxy Service - 特定组件)
- 功能: 一个专门设计用于防御 Server-Side Request Forgery (SSRF) 攻击的代理服务。
- 作用: 当 Dify 平台上的某些功能(例如:网页抓取插件、从 URL 加载数据集、某些插件功能)需要代表服务器发起对外部网络资源的 HTTP/HTTPS 请求时,这些请求会被强制路由通过这个
ssrf_proxy服务。- 安全控制: 该服务实施严格的安全策略,限制可以访问的目标主机、端口、协议(通常只允许 HTTP/HTTPS 到常见端口),并过滤危险的请求头和响应内容(如私有 IP 地址、AWS/GCP/Azure 元数据服务地址
169.254.169.254等)。 - 目的: 防止攻击者通过精心构造的输入(如恶意 URL),诱使服务器内部组件访问其本不该访问的内部系统(如数据库管理接口、云元数据服务获取凭证、内网应用),从而造成严重安全风险。
- 安全控制: 该服务实施严格的安全策略,限制可以访问的目标主机、端口、协议(通常只允许 HTTP/HTTPS 到常见端口),并过滤危险的请求头和响应内容(如私有 IP 地址、AWS/GCP/Azure 元数据服务地址
- 依赖: 被需要安全发起外部网络请求的组件调用,通常是
docker-worker-1(处理数据集 URL 加载、网页抓取插件任务) 或docker-plugin_daemon-1(执行需要网络访问的插件)。
切换到桌面端机器,打开浏览器,输入http://ip/,进行访问Dify,如图11所示。
图11 访问Dify
设置管理员账号:填写邮箱、用户名、密码后,再重新登录一下,如图12和图13所示。
图12 登录界面

图13 控制台界面
到此,Dify部署完成。
2.4 安装Gradio框架
因为Gradio是一个搭建可视化界面的Python库,所以首先需要有Python环境,此处是Python版本为Python3.7.3。安装Python开发环境以及Gradio框架。
首先下载并解压 Python 源码包,命令如下:
1 | [root@ollama docker]# cd /root/ |
创建全局软链接,使系统可以通过python3和pip3命令调用新安装的 Python 3.7.3 及其包管理器,命令如下:
1 | [root@ollama ~]# ln -s /usr/local/python3/bin/python3.7 /usr/bin/python3 |
最后验证Python版本和检查 Gradio 库是否安装成功:
1 | [root@ollama ~]# python3 --version |
验证是否有Gradio框架包,如果查询出来,则表示无需安装。
注意:本实验是连续实验,请不要释放实验环境。
3. 实战案例——大模型平台应用
3.1 将本地大模型与 Dify 进行关联
返回到Dify主界面,点击右上角用户名下的”设置”,如图14所示。

图14 设置
选择“模型供应商”,找到对应的 Ollama,点击“安装”按钮,如图15所示。然后跳转对话框再次点击“安装”按钮,如图16所示。

图15 点击“安装”
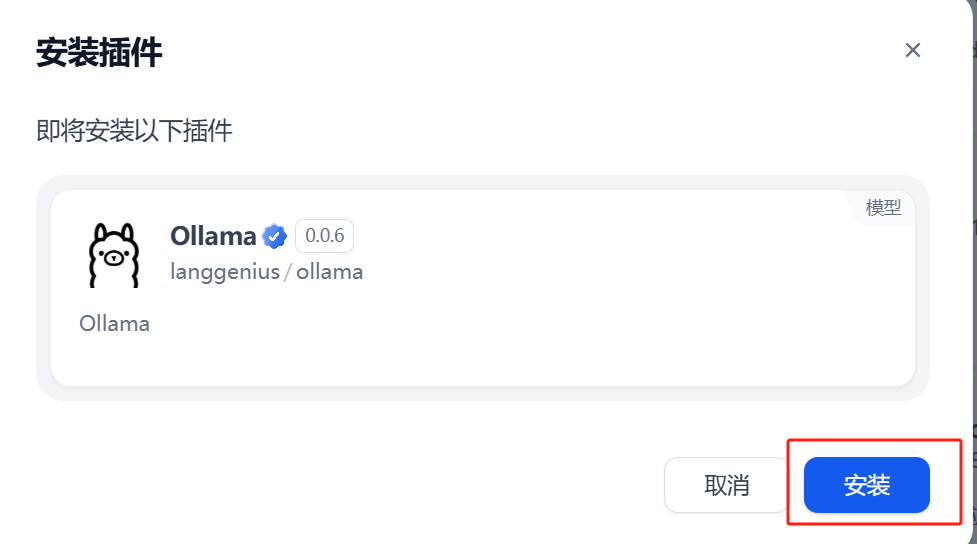
图16 安装插件
安装完成后,在“模型供应商”中找到Ollama插件,并点击“添加模型”,如图17所示。

图17 添加模型
添加模型的信息,通过以下命令来查看:
1 | [root@llama docker]# docker exec -it ollama ollama list |
填写模型对应的信息,然后点击“保存”按钮,如图18所示。
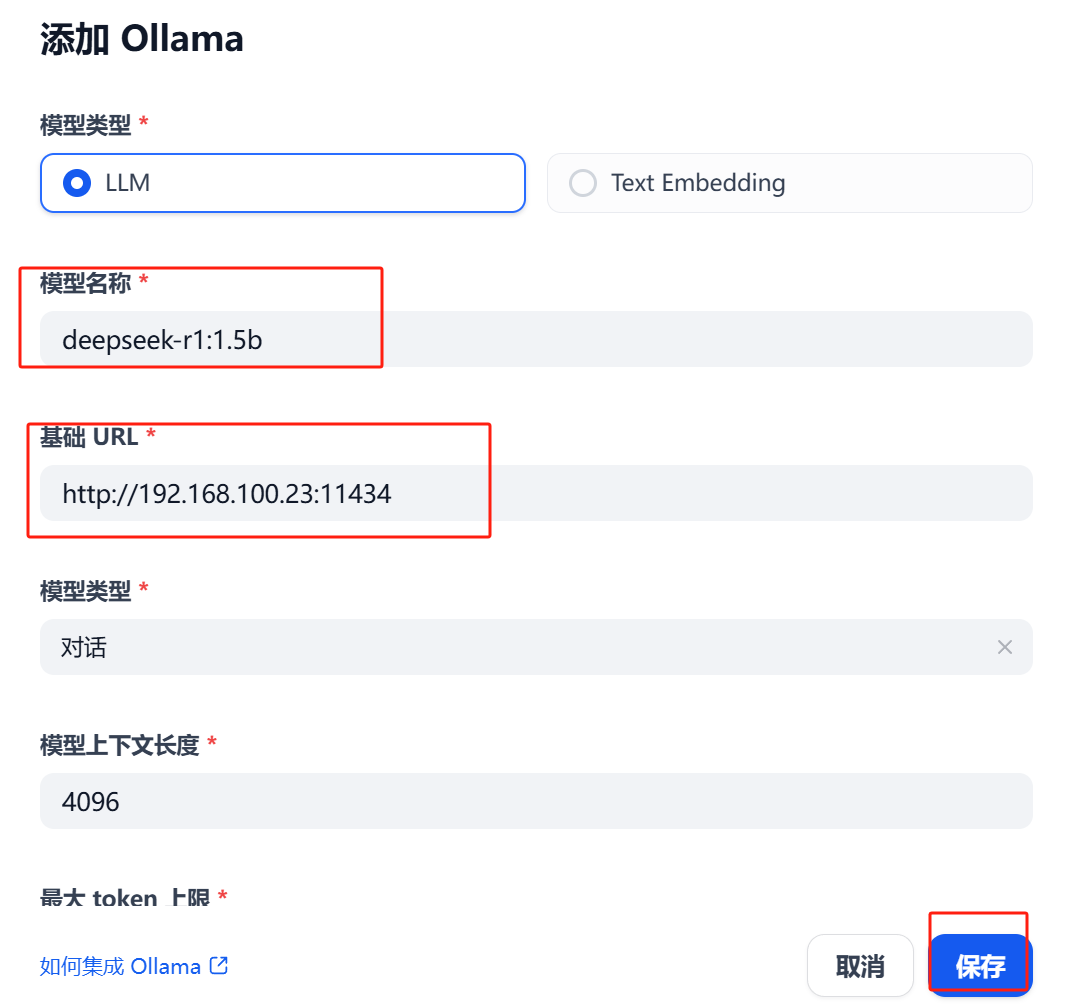
图18 填写模型对应的信息
保存过程中,插件容器会进行离线安装相关服务,在此期间可以通过以下命令来观察过程:
1 | [root@ollama docker]# docker logs docker-plugin_daemon-1 -f |
如图19所示,在日志中看到此结果,则表示可以正常添加模型。

图19 日志结果
Qwen模型按照同样步骤,添加成功后,如图20所示,可以看到两个模型已经加入到了Dify里。

图20 模型添加成功
添加好模型后,接下来是设置系统模型,刷新网页。点击右上角用户名下的“设置”,选择“模型供应商”,点击右侧的“系统模型设置”,如图21所示。

图21 系统模型设置
然后选择模型,点击“保存”,如图22所示。
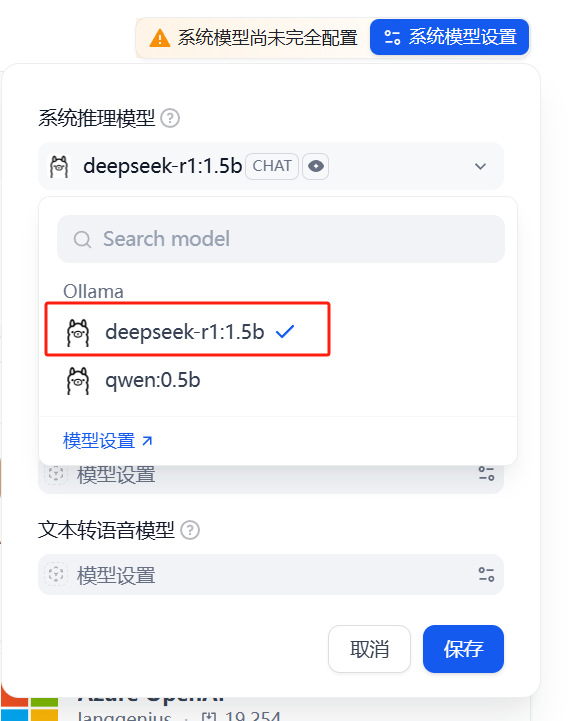
图22 选择模型
到此,Dify就与前面部署的本地大模型关联起来了。
3.2 创建聊天助手智能体应用
(1)创建空白应用
进入 Dify 主界面,点击“创建空白应用”,如图23所示:

图23 创建空白应用
选择“聊天助手”,输入自定义应用名称和描述,点击“创建”按钮,如图24所示。该调试界面如图25所示。

图24 选择聊天助手

图25 调试与预览界面
3.3 创建本地知识库
(1)添加Embedding 模型
Embedding模型可以把复杂的、高维的数据(比如文本、图像等)转换成低维的向量。这些向量虽然看起来只是数字,但它们能够很好地捕捉到数据的语义信息。
首先,它可以用于文本分类,比如判断一篇文章是正面评价还是负面评价;还可以用于相似性搜索,比如在海量的文本中快速找到和用户问题最相关的答案;甚至在推荐系统中,通过Embedding模型把用户和商品的特征转换成向量,就能更精准地给用户推荐他们可能喜欢的东西。
在搭建知识库的时候,我们上传的资料(比如文档、文章等)需要先通过Embedding模型转换成向量,然后存入向量数据库。这样,当有人提问的时候,系统就能通过自然语言理解问题,然后在向量数据库中快速、准确地找到相关的资料,从而给出准确的回答。所以,提前把私有数据向量化入库,是为了让知识库在回答问题时更高效、更准确。
点击右上角用户名下的“设置”,选择”模型供应商”,点击右侧的“添加模型”,如图26和图27所示:
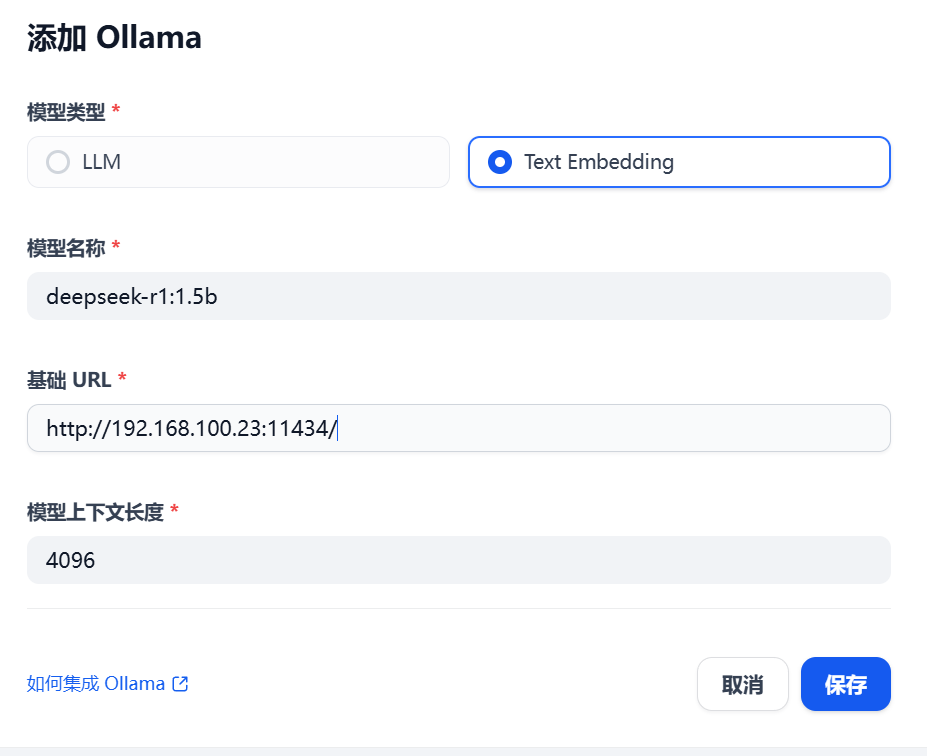
图26 添加Ollama

图27 添加成功
(2)创建知识库
返回 Dify 主界面,点击上方的“知识库”,点击“创建知识库”,如图28所示。

图28 创建知识库
在桌面端使用浏览器登陆到http://mirrors.douxuedu.com/newcloud/此地址,然后找到guicheng.docx,点击下载,下载到桌面端机器。
如图29所示,选择“导入已有文本”,上传资料(支持 TXT、PDF、Word、Excel 等格式,比如:可以上传一份企业内部的项目文档,或者个人的学习笔记)。
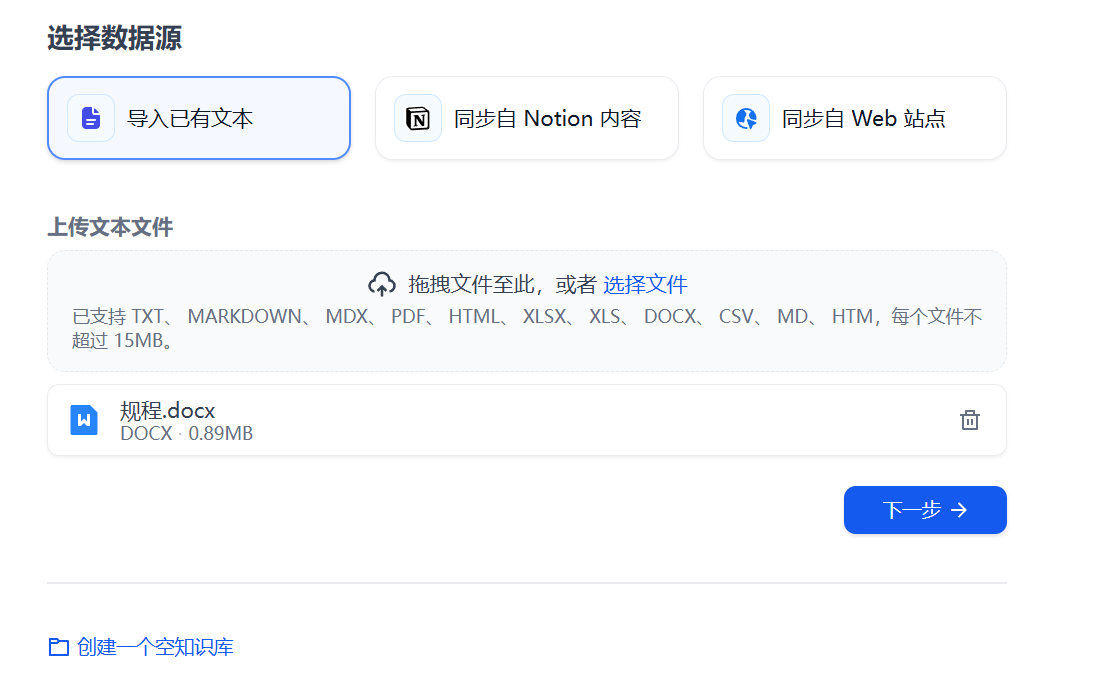
图29 导入已有文本
选择合适的模型,并配置相关参数后点击“保存并处理”,如图30和图31所示。
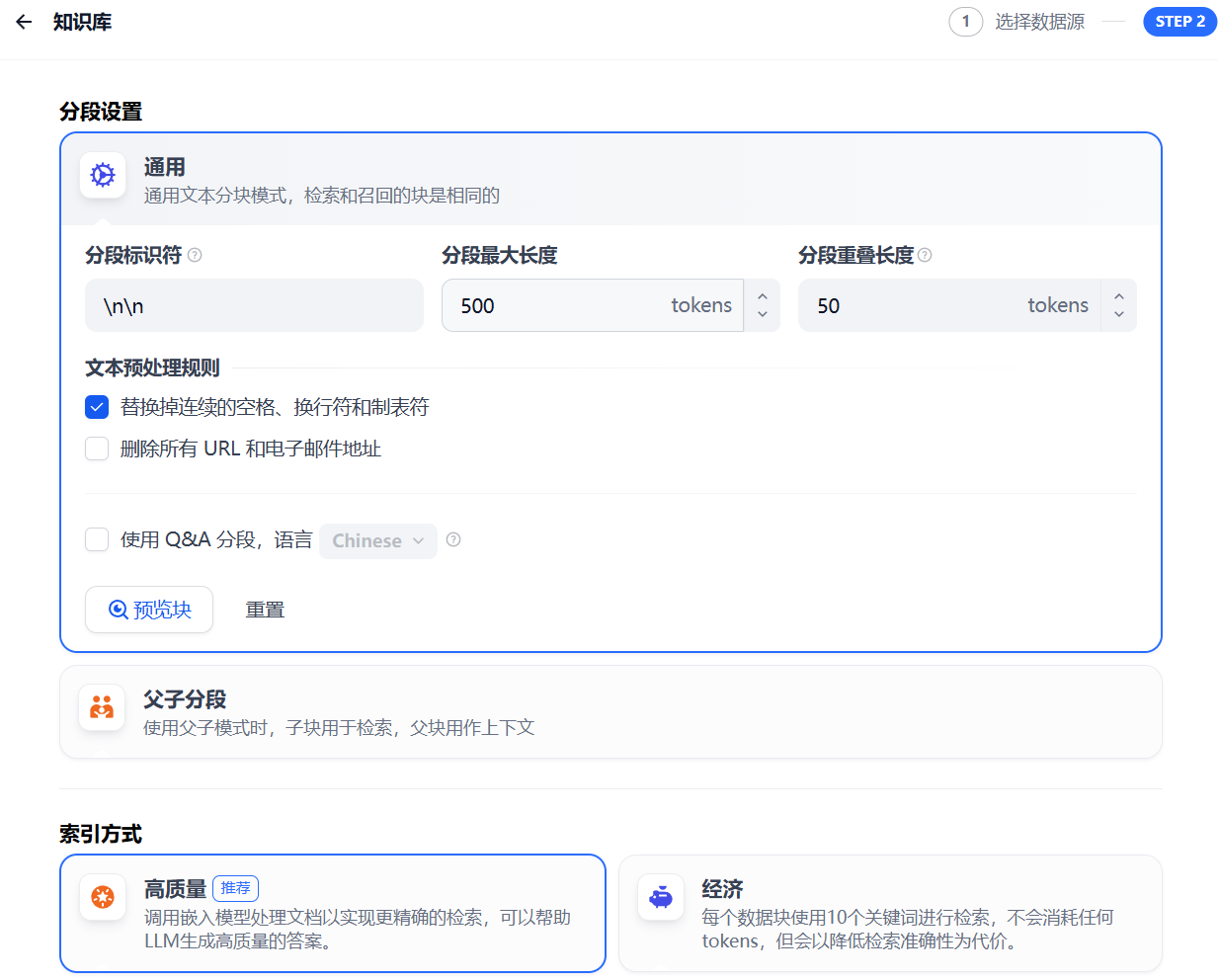
图30 配置相关参数

图31 保存并处理
耐心等待,系统会自动对上传的文档进行解析和向量化处理。这个过程可能需要几分钟,具体时间取决于文档的大小和复杂程度。完成后会出现“嵌入已完成”信息,如图32所示。
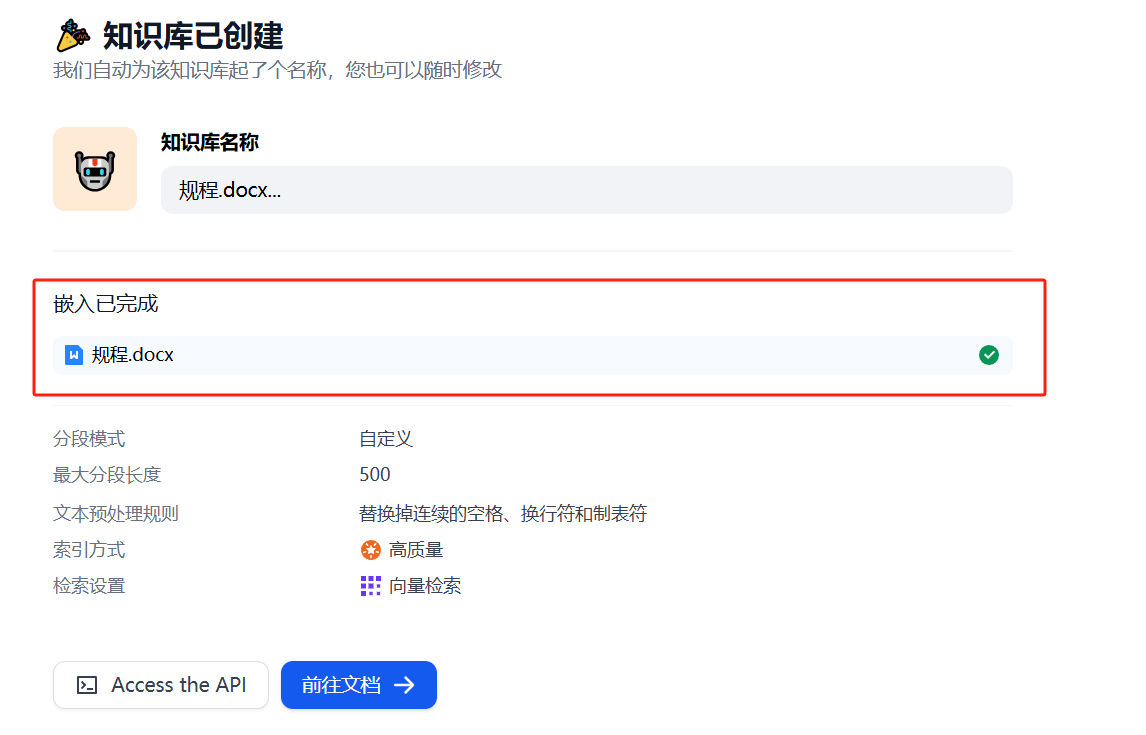
图32 嵌入已完成
创建成功后我们可以点击“前往文档”按钮,查看分段信息,如图33所示:
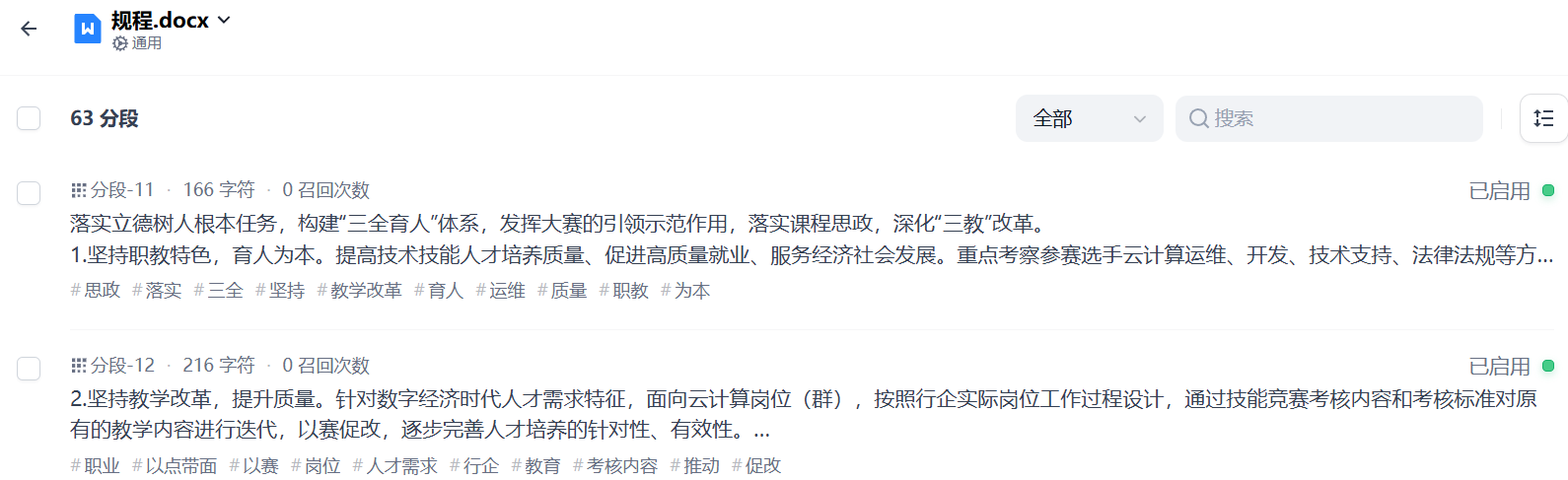
图33 查看分段信息
(3)为对话上下文添加知识库
返回 Dify 主界面,回到刚才的应用聊天页面,添加知识库,如图34所示:
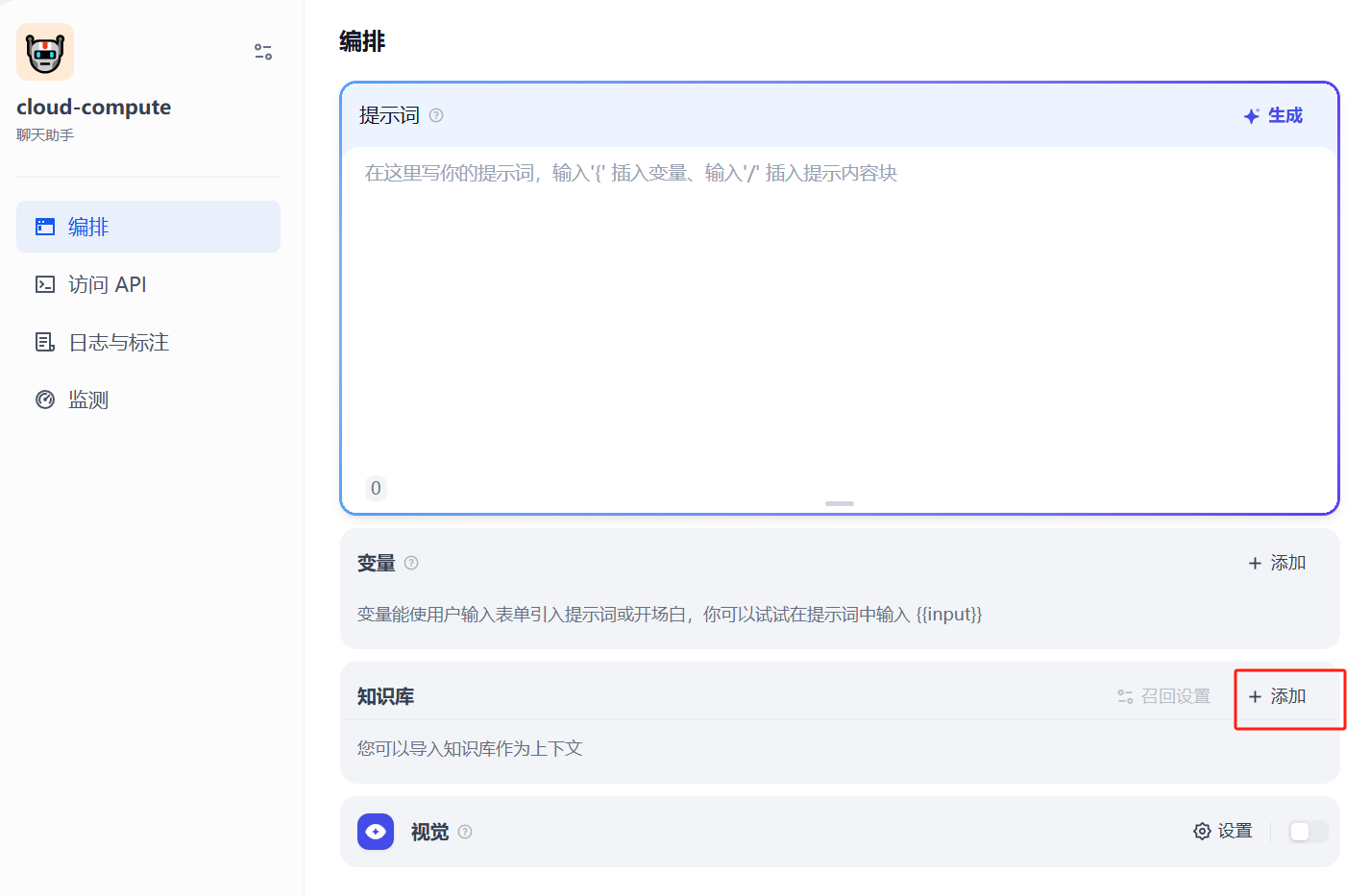
图34 添加知识库
然后选择刚刚创建的知识库,如图35所示:
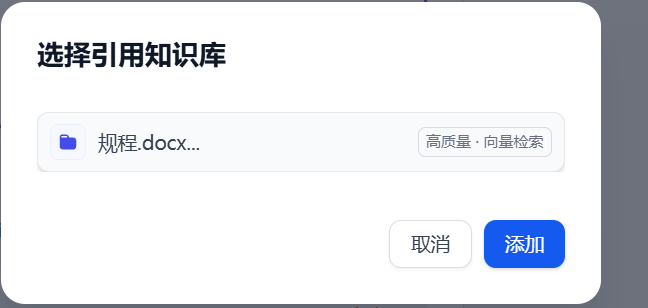
图35 选择知识库
选中后点击“添加”按钮,如图36所示:
图36 添加
选择刚才创建的知识库作为对话上下文。保存当前应用设置后,就可以测试了,如图37所示。
图37 测试
以上得出,DeepSeek的思考过程非常有特点,感觉就像有一个认真负责的人在仔细翻阅文档。它会把自己查找和分析的过程展示得很清楚,最后给出一个严谨的结论。如果你有一个专门的学术知识库,它不仅能帮你查找信息,还能进行推理、思考和总结,使用起来非常方便。
注意:本实验是连续实验,请不要释放实验环境。
4. 实战案例——大模型对接开发
将完整的代码文件下载到大模型节点,命令如下:
1 | [root@ollama ~]# curl -O http://mirrors.douxuedu.com/newcloud/chat.py |
基于Ollama模型管理和Gradio框架,可以快速搭建一个直观的聊天界面,代码名称为chat.py,查看该文件代码如下:
1 | [root@ollama ~]# cat chat.py |
使用以下命令运行代码:
1 | [root@ollama ~]# python3 /root/chat.py |
在浏览器中,输入http://ip:7860/访问页面,然后尝试在prompt中输入信息进行询问。例如输入“你是谁?”并提交,在output中会显示回答信息,如图38所示。

图37 访问页面
5. 项目总结
通过 Ollama + Gradio+ Deepseek这个组合,企业可以轻松搭建本地知识库,提升内部信息管理效率。无论是文档检索、问答系统还是自动化工作流,都能轻松搞定,行业典型应用如下:
(1)智能问答
系统通过集成DeepSeek和Qwen模型,实现了深度语言理解能力,能够准确捕捉用户问题的语义和意图。这种能力使得系统能够快速、准确地给出用户所需答案,无论问题涉及业务咨询、技术问题还是日常交流。这种深度语言理解与智能问答的紧密融合,显著提升了用户体验和系统的实用性。
(2)对话记录分析
系统具备对话记录与分析功能,能够记录用户的对话历史,并对其进行深入分析。通过挖掘用户的需求和行为模式,系统能够更好地了解用户,从而提供更加个性化的服务和建议。这种功能不仅提升了用户体验,还为系统的持续优化和改进提供了数据支持。